JSON-P: what it is, what it's not and how it works
I thought I'd take time out from discussing the brave new world of ECMA5 (to be continued) and do a post on JSON-P, since it's occured to me lately that it's often misunderstood by intermediate developers.
This post is aimed at developers who use JSON-P but have been been too sure about what it does under the bonnet. We'll pin down what it is, isn't, how it works, and some common misconceptions.
JSON-P in two sentences
JSON-P is means of loading data from a remote server, provided the server in question is expecting the request. It is not AJAX, and does not necessarily involve JSON.
How JSON-P works
JSON-P gets around the fact that JavaScript's Same Origin Policy prevents cross-domain AJAX by exploiting the fact that the src attribute of the script tag is not subject to this limitation, and can load in content (i.e. JavaScript) from remote servers.
Therefore, the steps of a JSON-P request are as follows:
- a new script tag is DOM-scripted into the page (or an old one is re-used)
- the request URL is applied to the script tag's src attribute
- the requested server loads our request and outputs a response
- the response is evaluated as JS, since we requested via a script tag
1var req = 'http://www.someserver.com/web_service';
2var script = document.createElement('script');
3script.src = req;
4document.head.appendChild(script);
If the server's response is...
alert('hello from someserver.com!');
...the alert will fire in our page once the request completes. Likewise, if the response is...
var something = 'hello from someserver.com!';
...a global variable, something, will be set in our page.
The key to understanding JSON-P is to remember that the server's response ultimately ends being evaluated as JavaScript, since it is called by a script tag.
These are simple examples. Usually, of course, you're going to want the server to give you some data.
Accessing the server response: assignment and callback
Normally we want our JSON-P request to result in one of two things happening:
- the data is passed to a globally-accessible callback function that we've prepared
- the data is assigned to a global variable
It must do one or the other, otherwise the response will not be accessible to our page's JavaScript. So if the server simply returned:
{name: 'Fido', type: 'Labrador', age: 3}
...that data would be unreachable - even though it's valid JavaScript. This is not a trait of JSON-P but of JavaScript itself, but it is a common stumbling block for developers new to JSON-P. Think about it; if a linked script in your page contains the above, without assigning it to a variable or passing it to a function, it is inaccessible.
Assignment
We saw variable assignment in the example further up. This is useful when, say, loading jQuery from CDN; we don't need the request to call a callback - we simply want jQuery to load. In other words, our JSON-P response should simply assign the variable jQuery (the jQuery namespace on which the library's API lives).
Callback
More common is for the response to call a callback function that we have prepared. For this, the server will need to know the name of the callback function; large, public JSON-P web services allows you to specify this in your request structure.
For example, the following is a request to Twitter's JSON-P web service to retrieve five Tweets that mention Paddington Bear:
'http://search.twitter.com/search.json?q=Paddington%20Bear&rrp=5&callback=my_callback_func'
If you run that in your browser, you'll see the web service outputs JS that passes the returned data, as JSON, to the callback I requested, my_callback_func().
Imagining the Twitter web service in simple terms, if it was built in PHP, it would look something like this: (I include this only for context; if you're a front-end-only developer, don't worry too much about this).
1//get JSON-encoded Tweets
2$tweetsJSON = get_tweets_json();
3
4//output
5if (isset($_GET['callback'])) echo $_GET['callback']."(";
6echo $tweetsJSON;
7if (isset($_GET['callback'])) echo ");";
The web service fetches and JSON-encodes the tweets, then builds an output string consisting of a call to our callback function, passing it the JSON as its only argument, i.e.
my_callback_func({ /* Twitter JSON here */ });
If we hadn't specified a callback, only the JSON would be output - useless for JSON-P requests but usable by server-side cross-domain requests (not relevant to this article).
As I touched on above, it is not always certain that you'll need to tell the web service the name of your callback function. If you control the web service, you may choose to hard-code the name of the callback on the server, so our PHP would look like:
1$data = get_some_data(); //get data and format as JSON
2echo "jsonp_callback(".$data.");";
There, the server assumes jsonp_callback - so your callback will have to be called that. This is a less common scenario, but illustrates the point that, whilst the ability to stipulate the name of your callback to the web service is a convenience, it is not a fundamental component of the JSON-P concept.
Callbacks with jQuery
We've established that our callback needs to be globally accessible. Given that, you might wonder how this, a typical JSON-P request with jQuery, works:
1$.ajax({
2 url: 'http://search.twitter.com/search.json?q=Paddington%20Bear&rrp=5&callback=?',
3 dataType: 'jsonp',
4 success: function(json) { console.log(json); }
5});
There, our callback is an anonymous function, clearly not globally accessible. What we don't see, though, is that jQuery redefines it globally, assigning it a randomly generated function name (to minimise name clashes with other global entities).
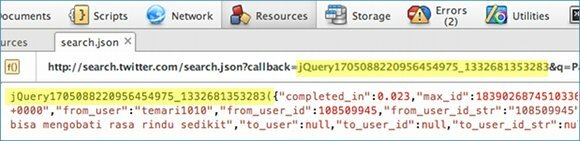
This is why we stipulated the name of our callback function as ? in the request URL rather than choosing it ourselves (though we could have done). This permits jQuery to handle this whole issue; sure enough, Opera's Dragonfly tools shows the actual request URL that was sent, and the global function that was created:
Misconceptions
Now we've taken a tour of what JSON-P is and how it works, some of the common misconceptions about should now seem obvious when you read them.
Misconception 1: JSON-P is a form of AJAX request
[UPDATE: granted, this depends on your definition of AJAX. I would hold that it's not a form of AJAX, but see the comments below for a discussion on this...]
This misconception is understandable for two reasons. Firstly, JSON-P involves the silent loading of data, just like AJAX. Secondly, jQuery implements JSON-P through its AJAX module, something that is understandable (i.e. to have a single section of the API concerned with data retrieval/submission) but can and does lead to this misconception.
As we've seen, though, JSON-P works by exploiting the src attribute of script tags, whereas AJAX requests are done over XMLHTTPRequest.
Misconception 2: JSON-P always involves JSON
The original proposal for JSON centred on the idea that servers would, on receipt of a JSON-P request, go off to the database (where applicable), get some rows of data, and serialise and output that data as JSON.
This is often the case - but it's not to say it has to be. The server response could equally be a string or a number, say.
Misconception 3: JSON-P requests must involve a callback
Again, most JSON-P web services do involve callbacks, but it does not have to be the case. As we saw early on, there's no need for callbacks when, say, loading jQuery over JSON-P - we simply want jQuery's jQuery global variable to be set.
Misconception 4: callbacks must be global functions
It's true that the callback function (or assigned variable) must be globally accessible, but this does not necessarily mean global in sense of being in the outermost scope.
1
If you're using a namespace pattern like above, i.e. where your entire code exists in a single namespace to avoid global pollution, there's no reason your callback function can't be a method of that namespace. So our Twitter request from above might become:
'http://search.twitter.com/search.json?q=Paddington%20Bear&rrp=5&callback=namespace.func2'
Likewise if the web service sets a variable rather than calling a callback. You could have the server do this:
1$data = get_some_data(); //get data and format as JSON
2echo "namespace.jsonp_data = ".$data.";";
So there you have it
So there you have it. If JSON-P was hazy for you before this, I hope I've helped clear up the issue and shown you how it works under the scenes. It's certainly one of the lesser understood elements of every-day web development, but it pays to understand precisely what's going on.
For more on JSON-P, be sure to check out Kyle Simpson's JSON-P.org.
10 comments | post newJavaScript getters and setters: varying approaches
Last week I posted an introductory article on ECMAScript 5 object properties, and the mini-revolution that I think they constitute. (The post made the coveted JavaScript Weekly - thanks, guys.)
One of the key features of them is the ability to define getter/setter callbacks on them.
Getters and setters are a means of providing an arm's-length way of getting or setting certain data, whilst keeping private other data, and are common of most languages. In JavasScript, setters are also a good way of ensuring your UI stays up to date as your data changes, which I'll show you an example implementation further down.
A new approach to getters and setters
The new approach looks like this, and can be used only on properties created via the new Object.create() and Object.definePropert[y/ies]() methods.
1var dog = {}, name;
2var name;
3Object.defineProperty(dog, 'name', {
4 get: function() { return name; },
5 set: function(newName) { name = newName; }
6});
7dog.name = 'Fido';
8alert(dog.name); //Fido
You'll note that this approach requires the help of a 'tracker variable' (in our case name) via which the getter/setter reference the property's value. This is to avoid maximum recursion errors that the following would cause:
1...
2 get: function() { return this.name; }, //MR error
3...
That happens because we set a getter, via which any attempt to read the property is routed. Therefore, having the getter reference this.name is effectively asking the getter to call itself - endlessly. Likewise for a setter, if it tried to assign to this.name.
Since each property needs its own tracker, and you don't want lots of variables flying around, it's a good idea to use a closure when declaring several properties.
1var dog = {}, props = {name: 'Fido', type: 'spaniel', age: 4};
2for (var prop in props)
3 (function() {
4 var propVal = props[prop];
5 Object.defineProperty(dog, prop, {
6 get: function() { return propVal; },
7 set: function(newVal) { propVal = newVal; }
8 });
9 })()
10alert(dog.name+' is a '+dog.type); //Fido is a spaniel
11dog.name = 'Rex';
12alert(dog.name+' is age '+dog.age); //Rex is age 4
There, we declare what properties we want on our object, and some start values. The loop sets each property, and tracks its value via a private propVal variable in its closure.
One of the things I like about this new approach is you no longer have to call the getters/setters explicitly (as you did with previous implementations - see below) - they fire simply by talking to the property.
Admittedly this has its proponents and its opponents; those in favour say getters/setters should fire simply by calling/assigning to the property - not calling some special methods to do that. Those against normally point out that someone new to the code might be surprised to find that talking to a property in fact fires a function.
My take is that, as long as this is part of the spec, and your code is well documented, there can be few complaints with using the new implementation.
Other ways of doing getters/setters
In any case, I much prefer them to the implementation we got in JavaScript 1.5.
1var dog = {
2 type: 'Labrador',
3 get foo() { return this.type; },
4 set foo(newType) { this.type = newType; }
5};
6alert(dog.type); //Labrador
7dog.foo = 'Rotweiller';
8alert(dog.foo); //Rotweiller
I've never been in love with this approach, chiefly because you don't deal directly with the property but with a proxy that represents its getter/setter callbacks - in the above example foo. The new approach does away with this; you call/assign to the property just as you would if there were no getters/setters in play, and the getter/setter callbacks kick in automatically - they are not referenced explicitly.
That said, one good point about this separation of property value from getter/setter is that the getter/setter can safely reference the property via this without the risk of recursion error, as befalls the new approach.
The older way
There's also the depracated __defineGetter__() and __defineSetter__() technique.
1var dog = {
2 type: 'Labrador'
3};
4dog.__defineGetter__('get', function() { return this.type; });
5alert(dog.get); //Labrador
Once again you have to name your setters/getters. By far the most notable point about this approach, though, is you can assign getters/setters after assigning the property - not a super common desire, but useful any time you don't want to or can't alter the prototype. The other two implementations don't allow you to do this, at least without a lot of reworking.
A final point about these latter implementations is that they don't hijack control of your property like the new implementation does. That is, if a developer ignores them and manipulates the property directly, they can. This is not good news; if you defined getters/setters, you probably want them to run, not be bypassed.
1var dog = {
2 name: 'Henry',
3 set foo(newName) { alert('Hi from the setter!'); this.name = newName; }
4};
5dog.name = 'Rex'; //setter bypassed; its alert doesn't fire
Setters and a responsive UI
As I mentioned in the intro, another role of getters in JavaScript can be to keep your UI up to date as your data changes. Frameworks like Backbone JS sell themselves heavily on this concept.
As the intro to the Backbone documentation points out, medium-large JavaScript applications can easily get bogged down with jQuery selectors and other means trying to keep your views in-sync with your data.
A getter can help here. Here's something I cooked up:
1Object.UIify = function(obj) {
2 for(var property in obj) {
3 var orig = obj[property];
4 (function() {
5 var propVal;
6 Object.defineProperty(obj, property, {
7 get: function() { return propVal; },
8 set: (function(target) {
9 return function(newVal) {
10 propVal = newVal;
11 $(target).text(propVal);
12 };
13 })(orig.target)
14 });
15 })()
16 obj[property] = orig.val;
17 }
18 return obj;
19};
20
21$(function() {
22 var dog = Object.UIify({name: {val: 'Fido', target: '#name'}, type: {val: 'Labrador', target: '#type'}});
23 dog.name = 'Bert';
24 dog.type = 'Rotweiller';
25});
And here's some example HTML:
Hi - my name's and I'm a !
I'll go into the details of what my method does in a further post. Essentially, though, what's happening is we pass an object to the UIify() method where each property is a sub-object containing its starting value (val) and a CSS/jQuery selector pointing to to the UI element that should be updated as and when the value changes (target.)
UIify() then returns an object using the new ECMA5 getters/setters. Whenever a property of the object is overwritten, the corresponding UI element denoted by the target we specified is updated. In my case, the targets were simply elements with IDs, but it could of course be more complex targets - it's just CSS/jQuery selector syntax.
---------
So there you have it, three approaches through the ages. Next time up I'll be looking more at the new Object funcionality in ECMA5.
(p.s. for further reading, be sure to check out the extensive MDN article on working with objects, which talks a lot about getter/setter techniques.)
8 comments | post newECMAScript 5: a revolution in object properties
Over the coming weeks I'm going to focus on discussing the mini revolution that ECMAScript 5 brought, and the implications in particular for objects and their properties.
ECMA5's final draft was published at the end of 2009, but it was only really when IE9 launched in early 2011 - and, with it, impressive compatibility for ECMA5 - that it became a genuinely usable prospect. Now in 2012, it is being used more and more as browser vendors support it and its power becomes apparent. (Full ECMA5 compatibility table).
JavaScript has always been a bit of an untyped, unruly free-for-all. ECMAScript 5 remedies that somewhat by giving you much greater control over what, if anything, can happen to object properties once changed - and it's this I'll be looking at in this first post.
A new approach to object properties
In fact the whole idea of an object property has changed; it's no longer a case of it simply being a name-value pairing - you can now dictate all sorts of configuration and behaviour for the property. The new configurations available to each property are:
- value - the property's value (obviously)
- writable - whether the property can be overwritten
- configurable - whether the property can be deleted or have its configuration properties changed
- enumerable - whether it will show up in a for-in loop
- get - a function to fire when the property's value is read
- set - a function to fire when the property's value is set
Collectively, these new configuration properties are called a property's descriptor. What's vital to understand, though, is that some are incompatible with others.
Two flavours of objects
The extensive MDN article on ECMAScript 5 properties suggests thinking of object properties in two flavours:
- data descriptors - a property that has a value. In its descriptor you can set value and writable but NOT get or set
-
accessor descriptors - a property described not by a value but by a pair of getter-setter functions. In its descriptor you can set get and set but NOT value or writable.
Note that enumerable and configurable are usable on both types of property. I'm struggling to understand why someone thought the ability to set a value and a setter function, for example, were incompatible desires. If I find out, I'll let you know.
New methods
To harness this new power, you need to define properties in one of three ways - all stored as new static methods of the base Object object:
- defineProperty()
- defineProperties()
- create()
The first two work identically except the latter allows you to set multiple properties in one go. As for Object.create(), I'll be covering that separately in a forthcoming post.
Object.defineProperty() is arguably the most important part of this new ECMAScript spec; as John Resig points out in his post on the new features, practically every other new feature relies on this methd.
Object.defineProperty() accepts three arguments:
- the object you wish to add a property to
- the name of the property you wish to add
- a descriptor object to configure the property (see descriptor properties above)
Let's see it in action.
1var obj1 = {};
2Object.defineProperty(obj1, 'newProp', {value: 'new value', writable: false});
3obj1.newProp = 'changed value';
4console.log(obj1.newProp); //new value - no overwritten
See how the overwrite failed? No error or warning is thrown - it simply fails silently. In ECMA5's new 'strict mode', though, it does throw an exception. (Thanks to Michiel van Eerd for pointing this out.)
There we set a data descriptor. Let's set an accessor descriptor instead.
1var obj = {}, newPropVal;
2Object.defineProperty(obj, 'newProp', {
3 get: function() { return newPropVal; },
4 set: function(newVal) { newPropVal = newVal; }
5});
6obj.newProp = 'new val';
7console.log(obj.newProp); //new val
You might be wondering what on earth is going on with that newPropVal variable. I'll come to that in my next post which will look at getters and setters in detail. Note also how, with our setter, the new value is forwarded to it as its only argument, as you'd expect.
The fact that these properties can be set only via these methods means you cannot create them by hand or in JSON files. So you can't do:
1var obj = {prop: {value: 'some val', writable: false}}; //etc
2obj.prop = 'overwritten'; //works; it's not write-protected
ECMA 5 properties don't replace old-style ones
An important thing to understand early on is that this new form of 'uber' property is not the default. If you define properties in the old way, they will behave like before.
1var obj = {prop: 'val'};
2obj.prop = 'new val'; //overwritte - no problemo
Reporting back
Note that these new configuration properties are, once set, not available via the API; rather, they are remembered in the ECMAScript engine itself. So you can't do this (using the example above):
console.log(obj1.newProp.writable); //error; newProp is not an object
Instead, you'll be needing Object.getOwnPropertyDescriptor. This takes two arguments - the object in question and the property you want to know about. It returns the same descriptor object you set above, so something like:
{value: 'new value', writable: true, configurable: true, enumerable: true}
More to come..
So there you go - a very exciting mini revolution, as I said. This new breed of intelligent object property really is at the heart of arguably the most major shake-up to the language for a long time. Next week I'll continue this theme - stay posted!
10 comments | post new
A friendly alternative to currying
I recently did a small talk and demonstration on currying in JavaScript. My personal take is that, while occasionally useful, it's a bit of a nuclear option, for limited reward.
Er, what's currying?
If you don't know, currying involves what's called partial application: invoking functions or methods whilst omitting some of the arguments, for which default values are assumed instead.
In other languages this is simpler. In PHP, for example, you can specify default values at the point of declaring your function:
1
2function someFunc($arg1 = 'default val') { echo $arg1; }
3someFunc(); //default val
4?>
Since that's not possible in JavaScript, the typical workaround is to feed your function to a curry-fier function, along with some default values, and get back a new version of your function that will assume default values for any omitted arguments. It might look something like this:
1//my simple function
2function add(num1, num2) { return num1 + num2; }
3
4//a curry-fier function
5function curryfy(func) {
6 var slice = Array.prototype.slice,
7 default_args = slice.call(arguments, 1);
8 return function() {
9 var args = slice.call(arguments);
10 for (var i=0, len=default_args.length; i 11 if (default_args[i] && (args[i] === null || args[i] === undefined)) 12 args[i] = default_args[i]; 13 return func.apply(this, args); 14 }; 15} 16 17//re-engineer our function to assume default values for omitted args 18var add = curryfy(add, 13, 14);
It's a little beyond the scope of this article to explain line-by-line what's going on there, but needless to say I can now call my add function with only some, or even no arguments.
1add(3, 4); //7
2add(); //27 - default values of 13 and 14 used
Drawbacks
That's all very nice. BUT, there are drawbacks and pitfalls to curry-fying. For one thing, a curryfied function no longer behaves as its originally-declared former self suggests. This might well throw a developer that comes to your code anew - particularly since JavaScript, as I say, does not support natively any notion of default function arguments.
Another problem concerns hoisting. If your function is a traditional one, i.e. as opposed to an anonymous function, the function itself will be hoisted, but its curryfied redefinition will not be (since curryfying a function always means declaring it as an anonymous function. For example:
1add(); //NaN - no values. Curryfied func doesn't exist yet.
2function add(num1, num2) { return num1 + num2; }
3var add = curryfy(add, 13, 14); //this time we redefine add as an anonymous function
4add(); //27
Our function is hoisted, since it's a traditional function not an anonymous one. That's the reason we can call it before the line where it's declared. However its curryfied redefinition will not be hoisted - so we would need to either curryfy it higher in the page or move our call to the function down.
A friendly alternative
My approach is rather different. Instead of redefining the function, let's ensure that it - and, indeed, every function - automatically inherits an extension to itself that allows us to omit variables. In addition, we'll set up another extension, called after the function is declared, that lets us set the default values. So the end result would be:
1function dog(breed, name) { alert(name+' is a '+breed); } //the func
2dog.setDefaults('poodle', 'Fido'); //set default value(s)
3dog('alsatian', 'Rex'); //call original version
4dog.withDefaults(null, 'Rex'); //call curryfied version
Hopefully it's clear what's happening there. I declare my function, then immediately stipulate what the default values are. Then, to invoke my function in such a way that I can have those default values substitute any omitted arguments, I call an extension of my function, called withDefaults(). To this I pass partial or even no arguments at all.
An advantage of this is that it doesn't destroy our original function, so anyone coming to our code anew and expecting traditional, not curryfied behaviour from our function, won't be surprised or confused.
Here's the code behind this approach:
1//function extension: allow version that uses default values
2Function.prototype.withDefaults = Function.withDefaults = function() {
3 var args = Array.prototype.slice.call(arguments);
4 if (this.defaults && this.defaults instanceof Object)
5 for (var i=0, len=this.defaults.length; i 6 if (this.defaults[i] && (args[i] === null || args[i] === undefined)) 7 args[i] = this.defaults[i]; 8 this.apply(this, args); 9 return (function(outerThis) { return function() { outerThis.apply(this, args); }; })(this);(this); 10} 11 12//function extension: set default values 13Function.prototype.setDefaults = function() { this.defaults = arguments; return this; }
As you can see, I'm declaring these two extensions on the Function object's prototype, so I can be sure they are both inherited by any and all functions I create.
I'll talk through the code in a separate blog post, but here's some usage demos for it, showing you different ways it can be used.
1//example 1: with traditional function
2function dog(name, breed) {
3 console.log(name+' is a '+breed);
4};
5dog.setDefaults(null, 'Daschund');
6dog.withDefaults('Fido');
7dog('Fido', 'spaniel');
8
9//example 2: with anonymous function
10var dog = function(name, breed) {
11 console.log(name+' is a '+breed);
12}.setDefaults('Jeremy', 'Bassetthound');
13dog.withDefaults('Kevin');
14dog('Josh', 'Bassetthound');
15
16//example 3: with instantiation
17var Dog = function (name, breed) {
18 this.name = name; this.breed = breed;
19}
20Dog.setDefaults('Russel', 'terrier');
21var dog1 = new (Dog.withDefaults());
22var dog2 = new Dog('Taz', 'labrador');
23console.log(dog1.name+' is a '+dog1.breed);
24console.log(dog2.name+' is a '+dog2.breed);
The output from that will be:
Example 1
1Fido is a Daschund
2Fido is a spaniel
Example 2
1Kevin is a Bassetthound
2Josh is a Bassetthound
Example 3
1Russel is a terrier
2Taz is a labrador
There's several interesting points of note there:
- When setting defaults for a function, you can specify values for as few or as many arguments as you like - it doesn't have to be all of them.
- When dealing with anonymous functions (example 2), you can call setDefaults() by chaining it to the end of your function literal.
- The approach even works with OO / instantiation, as shown in example 3. A lot of curryfyer scripts overlook this use case.
Phew. So, in summary?
You have a function. It accepts a lot of arguments. You find yourself passing many of the same arguments to it each time. Using the above script you can set some default values and then not have to worry about passing them as arguments when you call the function in future.
post a comment